Mon besoin
Donc, je souhaite avoir un cluster Kubernetes gratuit.
Bien sur, j'ai des critères en plus du coût qui doit rester nul :
- Que ça tourne sur le territoire français (idéalement chez un fournisseur lui-même français ou européen mais pour quelque chose de gratuit, je ne suis pas ferme sur ce point) ;
- Que le cluster soit infogéré (je ne veux pas lancer un
k3sou équivalent, je suis la flemme incarnée ) ; - Qu'il y ai au moins deux nœuds, comme ça lors des mises à jour il y en aurait toujours un en route pour les composants « essentiels » ;
- Avoir au moins 4 CPUs et 8Go de RAM en tout dans le cluster, ça peut paraître léger mais pour le stade de développement auquel je suis, ça suffira amplement.
Du coup, j'ai trouvé une réponse à tout ça, avec les points d'attention suivant :
- C'est géré par des américains (mais pas Amazon, ni Microsoft, ni Google, on va dire que c'est déjà ça) ;
- C'est bien dans une région française, il y a quelques autres régions européennes disponibles ;
- Les nœuds gratuits à vie ne sont pas en
amd64/x86_64mais en…aarch64(ouarm64si vous préférez) !
Je vais donc avoir un cluster gratuit, hébergé en France, avec une architecture ARM 64 bits.
Mais qui fourni gratuitement ces ressources ? Oracle Cloud Infrastructure (qu'on abrège apparemment OCI, ce qui me crée une petite confusion avec l'Open Containers Initiative mais je vais m'y faire).
À propos d'Oracle
Je ne suis pas fan d'Oracle, tout comme je ne suis pas fan des trois gros fournisseurs cloud américains (AWS, Azure et GCP).
En l'occurence, c'est le seul moyen que j'ai trouvé actuellement pour avoir un cluster Kubernetes gratuit : Oracle offre des nœuds aarch64 gratuitement à vie ! Pour prototyper, c'est génial : ça peut grimper à 8 cœurs de processeur et 24Go de RAM, divisables en une à quatre machines virtuelles.
Je n'aurais pas choisi Oracle s'il n'y avait eu aucune région disponible en Union Européenne, toutefois j'ai conscience qu'un doute plane sur la possibilité pour le gouvernement américain de réclamer des données hébergées chez des entreprises américaines, même en Union Européenne voire en France.
Si le sujet du Cloud Act vous intéresse, certais founisseurs proposent leurs solutions (sans évoquer les projets Bleu et S3NS) :
- AWS indique que chiffrer les données est suffisant alors qu'à l'époque de l'annonce du Cloud Act, ils indiquaient que les demandes des USA ne seraient pas applicables (ce qui contrastait avec ce que disait IBM, à savoir que le cadre imposé par le gouvernement américain n'était pas contournable) ;
- Azure cloisonne les données européenne, il me semble qu'à l'époque de l'annonce leur discours était nuancé et qu'ils évoquaient une possibilité de faire des remboursements en cas de demandes de données appliquées (c'est bien d'avoir un gros chéquier ) ;
Mise en place
Quelques concepts sur Oracle Cloud Infrastructure
On notera qu'Oracle permet de créer des compartments (soit des compartiments en français) et qu'un compte sur leur cloud fait partie d'un tenant (ça se traduit par « locataire » en français, je n'y avais jamais réfléchis malgré le fait que dans mon milieu on parle souvent de tenants).
Chaque tenant a un compartment par défaut nommé « root ». Personnellement j'en ai créé un spécifique pour mon projet.
Comme chez tout bon fournisseur cloud, on retrouvera (dans ce qui nous intéresse) :
- Des réseaux virtuels, nommés Virtual Cloud Networks et abrégés VCN ;
- Des sous-réseaux pour ces derniers, nommés subnets (rien de très original, tant mieux) ;
- Diverses gateways et IP à mettre dans les VCN ;
- Et le service de Kubernetes infogéré qui s'appelle Container Engine for Kubernetes et qui est abrégé OKE (donc ce n'est pas un acronyme puisque ça ne correspond pas au nom complet, c'est curieux mais ce n'est pas notre sujet du jour ).
Configurer le cluster Kubernetes
Je fais tout en « infrastructure as code » (qu'on abrège « IaC »), du coup cet exemple n'y échappe pas. Habituellement, j'utilise Terraform mais j'ai profité de cette occasion pour tester OpenTofu, le fork de Terraform sous licence réellement libre géré par la Linux Foundation (juste au cas où : le manifeste d'OpenTofu explique pourquoi ce fork a eu lieu) et ça a très bien fonctionné.
J'aime optimiser les choses et Oracle a eu la bonne idée de publier un module Terraform qui crée toutes les ressources nécessaires, ce qui permet de gagner beaucoup de temps !
Voici le code HCL qui permet d'utiliser ce module, avec des commentaires pour donner quelques détails. En réalité j'ai utilisé beaucoup de variables, que j'ai remplacées ici par des valeurs fixes pour l'exemple (sauf pour les choses qu'il faut, à mon avis, absolument passer en variables).
1 terraform {
2 required_version = ">= 1.6"
3
4 required_providers {
5 oci = {
6 source = "oracle/oci"
7 # J'utilise Renovate pour mettre à jour automatiquement la version, d'où le fait que j'utilise une version précise.
8 version = "5.36.0"
9 }
10 }
11 }
12
13 # Ces valeurs me permettent d'avoir une petite cohérence dans mes ressources quand je vais voir sur l'interface d'Oracle Cloud Infrastructure.
14 locals {
15 app_name = "example-application"
16 environment = "development"
17
18 resource_name = "${app_name}-${environment}"
19 tags = {
20 "name" = local.app_name,
21 "environment" = local.environment,
22 }
23 }
24
25 # On doit fournir une IP déjà créée pour que les nœuds aient accès à internet, c'est dommage mais pourquoi pas.
26 resource "oci_core_public_ip" "example" {
27 compartment_id = var.oracle_compartment_ocid
28
29 display_name = local.resource_name
30 freeform_tags = local.tags
31
32 lifetime = "RESERVED"
33 }
34
35 module "example" {
36 depends_on = [resource.oci_core_public_ip.example]
37
38 source = "oracle-terraform-modules/oke/oci"
39 # Comme pour le provider, le module sera mis à jour automatiquement par Renovate.
40 version = "5.1.4"
41 providers = {
42 oci.home = oci
43 }
44
45 compartment_id = var.oracle_compartment_ocid
46 home_region = "eu-paris-1"
47 region = "eu-paris-1"
48
49 # Je n'ai aucune honte : tout se nommera pareil et aura les mêmes tags.
50 vcn_name = local.resource_name
51 cluster_name = local.resource_name
52 freeform_tags = {
53 bastion = local.tags,
54 cluster = local.tags,
55 iam = local.tags,
56 network = local.tags,
57 operator = local.tags,
58 persistent_volume = local.tags,
59 service_lb = local.tags,
60 workers = local.tags,
61 }
62
63 # Le label DNS permet d'avoir des noms DNS « propres » pour les nœuds dans leur réseau, en vrai ça m'est complètement inutile mais je le renseigne pour le principe.
64 vcn_dns_label = "example"
65
66 # L'operator est une machine qui permet de gérer le cluster avec kubectl et Helm depuis le réseau du cloud, je ne souhaite pas faire ça.
67 create_operator = false
68
69 # De la meme manière, le bastion permet de se SSH dans les nœuds directement depuis le réseau du cloud, ce qui ne m'intéresse pas.
70 create_bastion = false
71
72 # Je souhaite accéder au cluster depuis mon PC local, donc le control plane doit être publique, avec une IP assignée.
73 control_plane_is_public = true
74 assign_public_ip_to_control_plane = true
75 # Ce paramètre n'est pas compatible IPv6 donc j'ai mis seulement mon IPv4, avec un `/32` à la fin pour qu'elle soit vue comme un bloc CIDR.
76 # Donc je ne peux accéder au control plane que depuis chez moi.
77 # Il est possible de mettre `["0.0.0.0/0"]` mais quand même, la sécurité…
78 control_plane_allowed_cidrs = var.kubernetes_control_plane_allowed_cidrs
79
80 # Voilà donc l'IP publique pour que les nœuds et les pods puissent accéder à internet.
81 nat_gateway_public_ip_id = resource.oci_core_public_ip.example.id
82
83 # Attention à bien rester à jour !
84 # Je n'ai as trouvé de système d'auto-upgrade de Kubernetes chez Oracle Cloud Infrastructure, dommage.
85 # Chez les autres fournisseur, c'est généralement disponible donc on indique seulement la version globale qu'on veut, par exemple `v1.29`, et une fenêtre de maintenance qui fait que le fournisseur cloud patche les nœuds quand il le faut.
86 kubernetes_version = "v1.29.1"
87
88 # Ce sont les valeurs par défaut, pour le coup je suis plutôt Debian qu'autre chose coté serveur mais je me dis que quitte à être chez Oracle, autant utiliser leur OS qui est probablement optimisé pour les machines virtuelles fournies.
89 worker_image_os = "Oracle Linux"
90 worker_image_os_version = "8"
91
92 worker_pools = {
93 "${local.resource_name}-main" = {
94 # Il faut préciser que le groupe de nœuds doit être créé, pourquoi pas hein !
95 create = true
96
97 # Je commence doucement avec deux nœuds.
98 size = 2
99
100 # J'utilise des machines basées sur un processeur Ampere 1.
101 shape = "VM.Standard.A1.Flex"
102 # Je rappelle qu'un OCPU vaut « au moins » deux CPU virtuels.
103 ocpus = 1
104 # La RAM est en gigaoctets.
105 memory = 6
106 # Le volume de démarrage est en gigaoctets et 50Go est sa taille minimale requise (j'ai essayé moins, l'APi a retourné une erreur indiquant que 50Go est le minimum).
107 boot_volume_size = 50 # this is the minimum
108
109 # Je ne veux pas que deux nœuds soient indisponibles en même temps.
110 node_cycling_enabled = true
111 node_cycling_max_surge = 0
112 node_cycling_max_unavailable = 1
113 }
114 }
115 }
116
117 # Voilà comment on récupère un fichier kubeconfig avec accès publique.
118 data "oci_containerengine_cluster_kube_config" "kube_config" {
119 depends_on = [module.example]
120
121 cluster_id = module.example.cluster_id
122 endpoint = "PUBLIC_ENDPOINT"
123 }
124
125 # Et voilà comment on l'enregistre dans un coin.
126 resource "local_file" "kube_config" {
127 depends_on = [data.oci_containerengine_cluster_kube_config.kube_config]
128
129 content = data.oci_containerengine_cluster_kube_config.kube_config.content
130 filename = "${abspath(path.root)}/kubeconfig.yaml"
131 }
Démarrer le cluster
Le fichier c'est bien, avoir le cluster en bonne et due forme c'est mieux !
Déjà on n'oublie pas de configurer le provider en exportant les variables d'environnement nécessaires, sachant que je me connecte avec une clé d'API créée pour mon compte (chez Oracle ce sont des clés RSA, après tout pourquoi pas) :
TF_VAR_oracle_compartment_ocid="<votre-compartment-ocid>"
TF_VAR_tenancy_ocid="<votre-tenancy-id>"
TF_VAR_user_ocid="…"
TF_VAR_fingerprint="…" # fingerprint de la clé d'API utilisée
TF_VAR_private_key_path="…" # chemin vers le fichier PEM de la clé privée
TF_VAR_region="eu-paris-1" # en France, évidemment, d'ailleurs il y a une région à Marseille
TF_VAR_kubernetes_control_plane_allowed_cidrs='["<votre-ip-fixe>/32"]' # attention, c'est un tableau dans une string!
Ensuite, j'ai dû appliquer en plusieurs fois car une ressource ne peut ête créée avant que les autres ne le soient, donc j'ai fait trois apply pour m'assurer que ça voulait bien se lancer (on notera que tofu peut être remplacé par terraform) :
# …
# …
Et normalement, si on va sur l'interface d'Oracle Cloud Infrastructure, tout est bon !
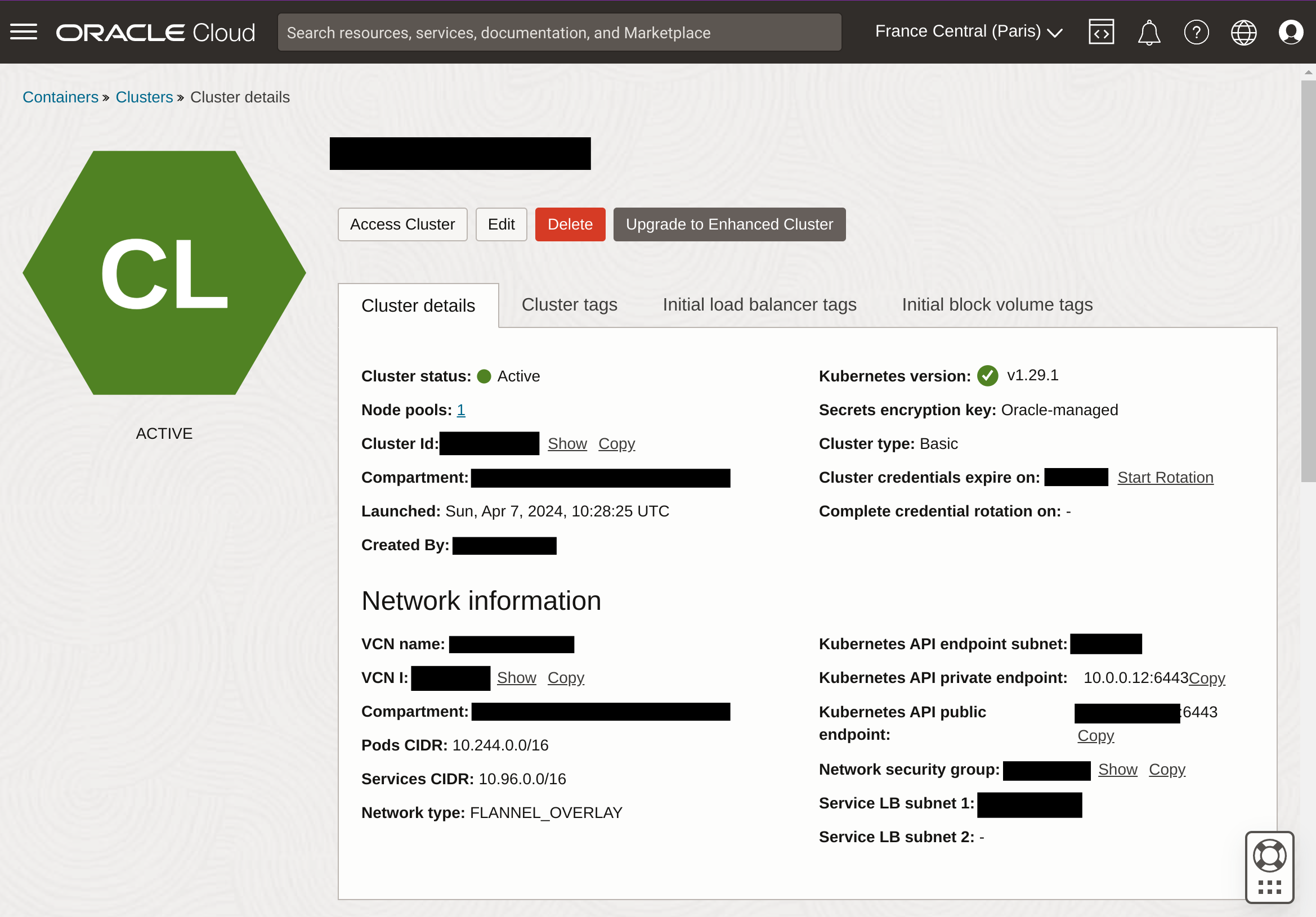
Accéder au cluster avec kubectl
On a un kubeconfig.yaml qui est généré par le code que j'ai proposé mais en l'utilisant, on verra qu'il nous manque un élément important : la CLI OCI qui permet de générer le token de connexion ! En effet, en décorticant le fichier kubeconfig, on voit que l'authentification est gérée par cette fameuse CLI :
1 users:
2 - name: user-[REDACTED]
3 user:
4 exec:
5 apiVersion: client.authentication.k8s.io/v1beta1
6 command: oci
7 args:
8 - ce
9 - cluster
10 - generate-token
11 - --cluster-id
12 -
13 - --region
14 - eu-paris-1
Vous aurez deux choix pour installer la CLI :
- Les instructions officielles ou…
- … un petit
python3 -m pip install oci-cli(avec éventuellement--break-system-packagessi vous avec le même empressement que moi).
Ça vaut dire aussi qu'il faut avoir son fichier ~/.oci/config, que vous obtiendrez en générant votre clé d'API (qui, je le rappelle, est une clé RSA).
Après ça, un petit kubectl get nodes devrait vous prouver que tout fonctionne parfaitement et que vous avez deux nœuds qui sont en fonctionnement.
Utilisation
Consommation de base
Par défaut, le serveur de métriques n'est pas installé. Je l'ai donc appliqué manuellement, vite-fait bien-fait (à l'avenir je ferai en sorte qu'il soit ajouté par mon outil GitOps, avec une version fixe et toutes les recommandations habituelles) :
Après une petite minute durant laquelle je laissais le serveur de métriques collecter quelques informations, j'ai pu voir les consommations des nœuds :
) )
En réalité, en faisant un kubectl top pods --all-namespaces et en additionnant la RAM réellement utilisée par chaque pod, j'obtiens environ 220Mi consommés (celle des nodes est en fait l'addition des limites de RAM de chaque pod, qui sont « surestimées » par rapport à l'utilisation que j'en aurais). Sachant que j'ai mis deux nœuds avec chacun six gigaoctets de RAM et qu'on peut même grimper à 24Go gratuitement, j'ai de la marge !
Installation
Pour ce projet, il m'arrivait de lancer des clusters chez des fournisseurs cloud et de les détruire peu de temps après donc j'ai fait en sorte de me faciliter la tâche au niveau du démarrage.
Du coup, j'ai un petit script (en fait, un Justfile) qui installe les composants de base dans mon cluster. Ça installe notamment ArgoCD qui va lui-même ajouter beaucoup de choses : des opérateurs de gestion de bases de données, Tekton et des pipelines que j'ai créé, un registre Docker léger, Renovate pour faire les mises à jour, etc.
J'ai quand même eu deux problème de compatibilité avec des outils que j'utilise :
- L'opérateur de CockroachDB ne propose que des images en
amd64, toutefois un ticket est ouvert pour avoir des images aarch64 et une personne a précisé en commentaire avoir construit une image pouraarch64(attention, elle a une version de retard, je ferais peut-être une nouvelle image à jour moi-même) ; - Le registre d'images Zot propose des images en
aarch64mais ce ne sont pas des images à architectures multiples donc il faut préciser dans les valeurs Helm qu'on veut utiliser leur registreaarch64.
Et bien sûr, mon application était jusque là compilée pour des processeurs amd64 mais je devrais être en mesure de régler ça facilement (j'espère ).
Conclusion
Que dire ? Ça fonctionne, à première vue. Je pense mettre à jour cet article dans un mois environ (ou en faire un nouveau si j'ai beaucoup de choses à dire) pour indiquer si la consommation financière est bien restée nulle selon Oracle (j'ai 250€ de crédit vu que je viens d'y créer mon compte et je peux voir ce qui m'en reste) et si tout fonctionne toujours.
Du coup, voilà les points positifs que je trouve « à chaud » :
- Le module fourni par Oracle pour
OpenTofu/Terraformest complet et permet de démarrer facilement sur leur cloud ; - La consommation de base sur les nœuds est normale (pas de mauvaise surprise) ;
- On peut avoir jusqu'à 8 cœurs de CPU (4 OCPU) et 24Go de RAM, ce qui est plutôt généreux !
Et le négatif que je vois à l'heure actuelle :
- Le module fourni par Oracle nécessite de faire des
tofu apply/terraform applyen plusieurs fois avec des-targetpour ne pas refuser de démarrer l'infrastructure, ça m'a fait batailler un peu au début ; - Le seul CNI proposé est Flannel (et un autre spécifique qui s'intègre aux réseaux virtuels d'Oracle Cloud) et si on veut installer Cilium, il faut activer l'operator dans leur module, ce qui fait une machine qui tourne inutilement (je vais me débrouiller autrement) ;
Il me surprend aussi qu'en 2024, il y ai des « incompatibilités » avec l'architecture aarch64 mais heureusement elles se contournent. Je ne met pas ça dans les points négatifs car ce n'est pas la faute d'Oracle, qui a la gentillesse de fournir des nœuds gratuits sous cette architecture donc je ne vais pas cracher dans la soupe.
Sur ce, je vais tenter de compiler mon application pour cette architecture et je vous dis « à bientôt » pour voir si le prix s'élève bien à 0€ !